Abstract
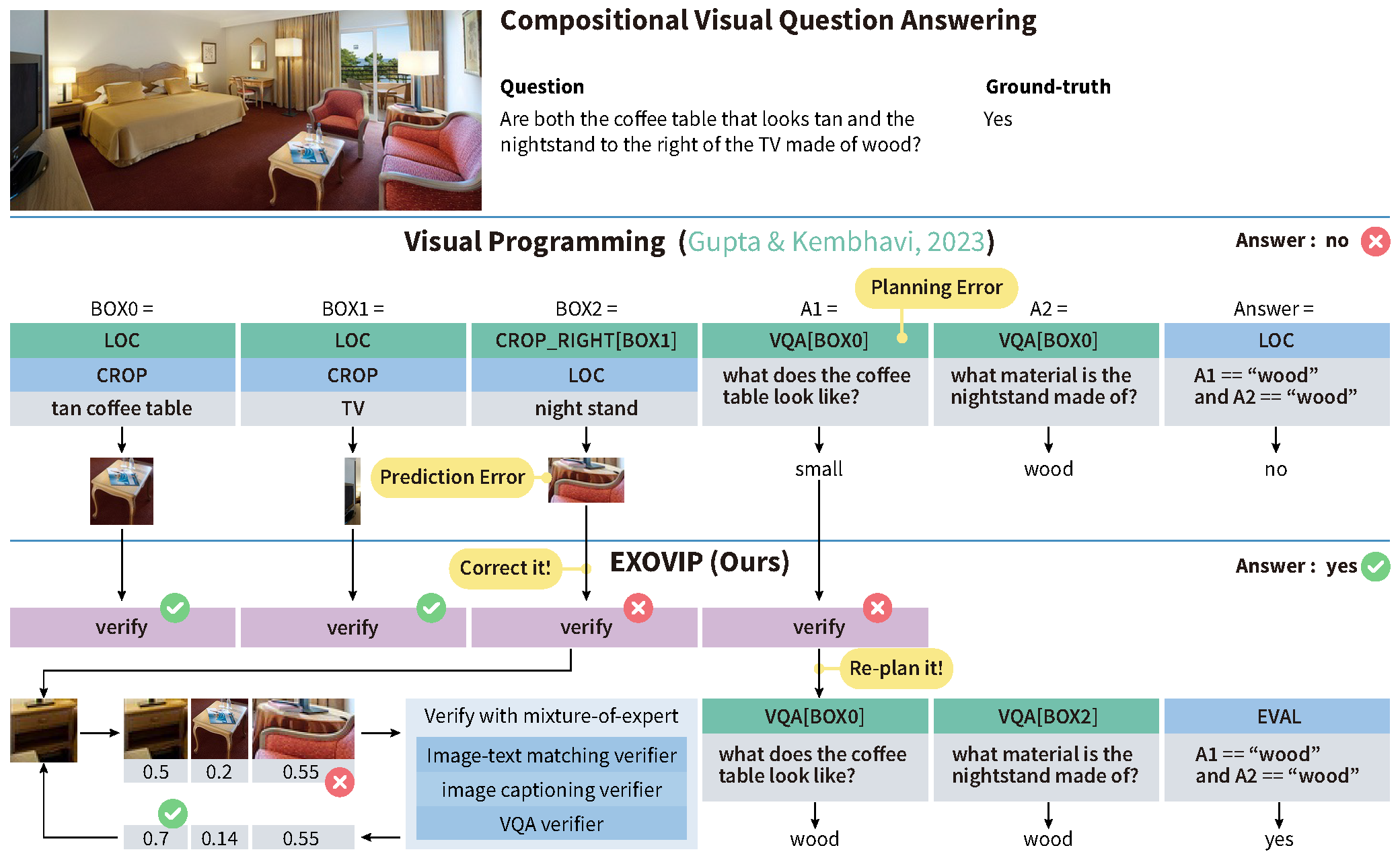
Compositional visual reasoning methods, which translate a complex query into a structured composition of feasible visual tasks, have exhibited a strong potential in complicated multi-modal tasks. Empowered by recent advances in large language models (LLMs), this multi-modal challenge has been brought to a new stage by treating LLMs as few-shot/zero-shot planners, i.e., vision-language (VL) programming. Such methods, despite their numerous merits, suffer from challenges due to LLM planning mistakes or inaccuracy of visual execution modules, lagging behind the non-compositional models. In this work, we devise a “plug-and-play” method, ExoViP, to correct errors in both the planning and execution stages through introspective verification. We employ verification modules as “exoskeletons” to enhance current VL programming schemes. Specifically, our proposed verification module utilizes a mixture of three sub-verifiers to validate predictions after each reasoning step, subsequently calibrating the visual module predictions and refining the reasoning trace planned by LLMs. Experimental results on two representative VL programming methods showcase consistent improvements on five compositional reasoning tasks on standard benchmarks. In light of this, we believe that ExoViP can foster better performance and generalization on open-domain multi-modal challenges.
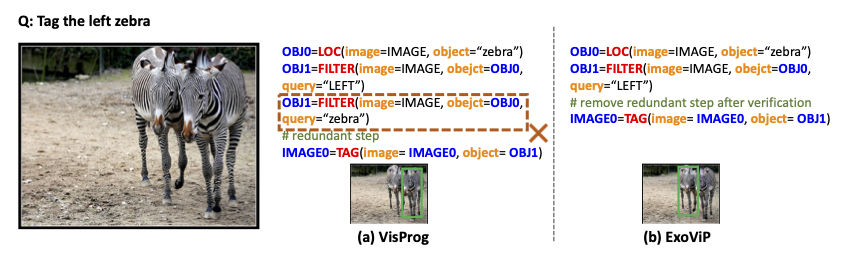
ExoViP
Exploration with Verification
- Image-text matching verifier
- Image captioning verifier
- Visual question-answering (VQA) verifier
- Negative Sampling We take the difference of a candidate answer \(ans\) with its semantic opposites \(neg\) as the final verification score, i.e., \(s = s_{ans} - s_{neg}\).
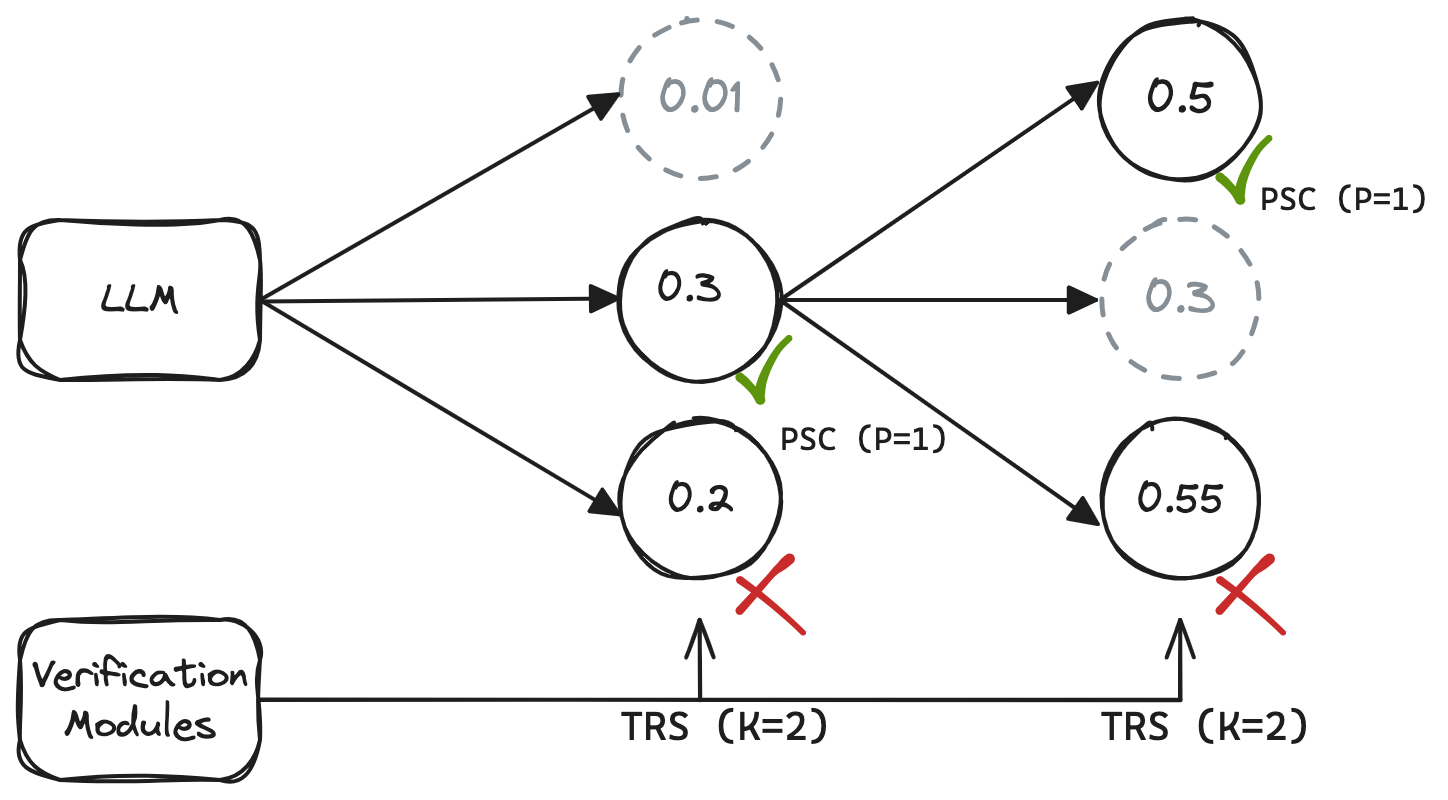
Exploration with Reasoning Trace
Tree-based reasoning trace searching (TRS) The reasoning trace searching procedure is represented as a tree structure, where each node is a reasoning operation. To get a better reasoning trace, we search from the tree using the beam search algorithm.
Post-hoc self-correction (PSC) We use the self-correctness ability of LLMs to rank the \(K\) traces and select the top \(P\) from them (\(P<K\)).
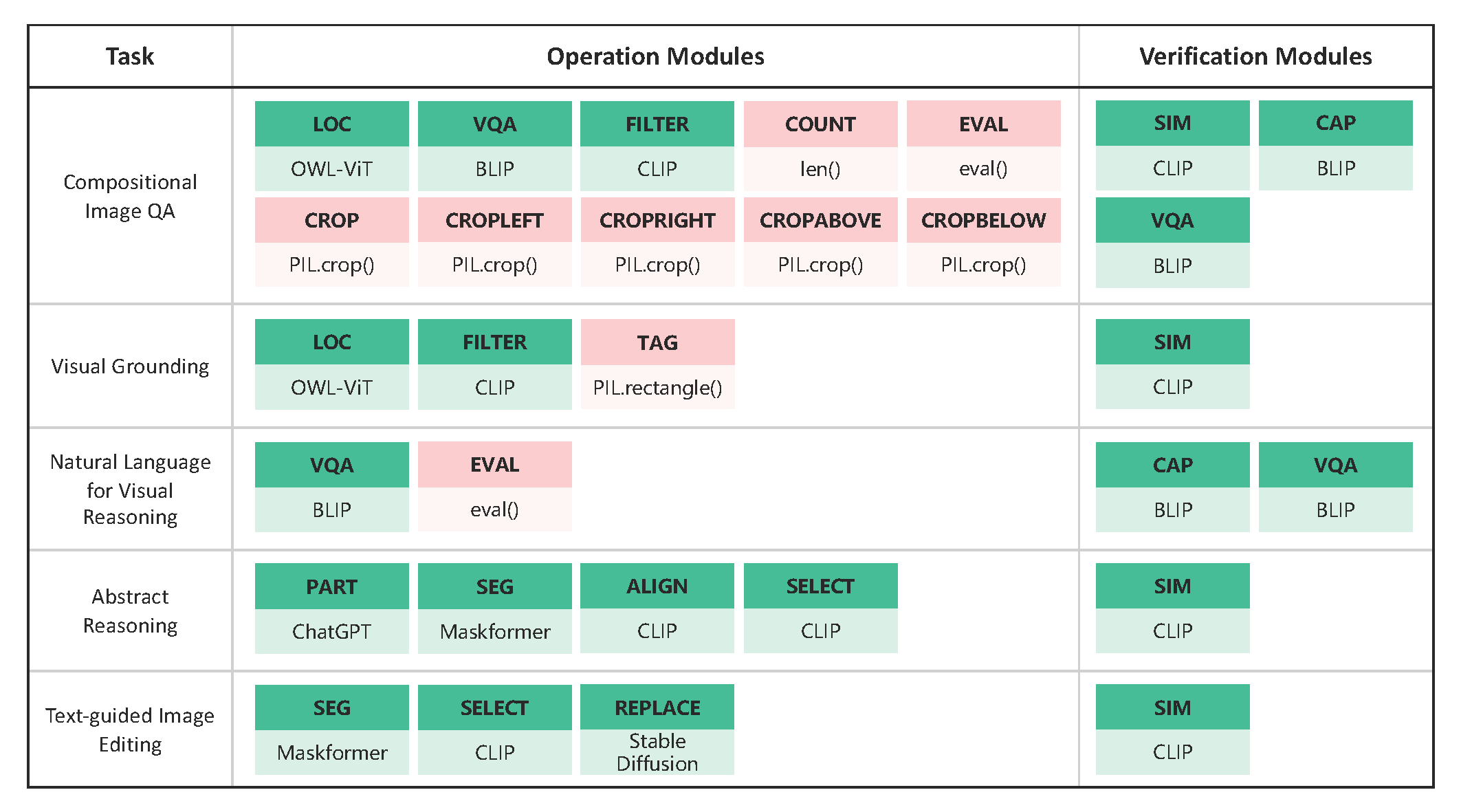
Downstream Tasks



BibTex
@inproceedings{wang2024exovip,
title={ExoViP: Step-by-step Verification and Exploration with Exoskeleton Modules for Compositional Visual Reasoning},
author={Wang, Yuxuan and Yuille, Alan and Li, Zhuowan and Zheng, Zilong},
booktitle={The first Conference on Language Modeling (CoLM)},
year={2024}
}